Continuous Benchmark Tool
What is the Continuous Benchmark Tool?
Continuous Benchmark Tool allows you to continuously benchmark the Vald cluster.
Assumed use case is:
- Verification with workload close to the production environment
- Verification before service installation when Vald version up
Architecture
Continuous Benchmark Tool has following 2 components:
- Benchmark Operator: Manages benchmark jobs
- Benchmark Job: Executes CRUD request to the target Vald cluster
Benchmark component and its feature
Benchmark Operator
- Manages benchmark jobs according to applied manifest.
- Apply method:
- Scenario method: one manifest with multiple benchmark jobs
- Job method: one manifest with one benchmark job
Benchmark Job
- Executes CRUD request to the target Vald cluster based on defined config.
- Execute steps are:
- Load dataset (valid only for HDF5 format)
- Execute request with load dataset
Benchmark CRD
Benchmark workload can be set by applying the Kubernetes Custom Resources(CRDs), ValdBenchmarkScenarioResource or ValdBenchmarkJobResource.
Benchmark Operator manages benchmark job according to the applied manifest.
ValdBenchmarkJob
ValdBenchmarkJob is used for executing single benchmark job.
And, Benchmark Operator also applies it to the Kubernetes cluster based on ValdBenchmarkScenarioResource.
main properties
| Name | mandatory | Description | type | sample |
|---|---|---|---|---|
| target | * | target Vald cluster | object | ref: target |
| dataset | * | dataset information | object | ref: dataset |
| job_type | * | execute job type | string enum: [insert, update, upsert, remove, search, getobject, exists] | search |
| repetition | the number of job repetitions default: 1 | integer | 1 | |
| replica | the number of job concurrent job executions default: 1 | integer | 2 | |
| rps | designed request per sec to the target cluster default: 1000 | integer | 1000 | |
| concurrency_limit | goroutine count limit for rps adjustment default: 200 | integer | 20 | |
| ttl_seconds_after_finished | time until deletion of Pod after job end default: 600 | integer | 120 | |
| insert_config | request config for insert job | object | ref: config | |
| update_config | request config for update job | object | ref: config | |
| upsert_config | request config for upsert job | object | ref: config | |
| search_config | request config for search job | object | ref: config | |
| remove_config | request config for remove job | object | ref: config | |
| object_config | request config for object job | object | ref: config | |
| client_config | gRPC client config for running benchmark job Tune if can not getting the expected performance with default config. | object | ref: defaults.grpc | |
| server_config | server config for benchmark job pod Tune if can not getting the expected performance with default config. | object | ref: defaults.server_config |
target
- target Vald cluster information
- type: object
| property | mandatory | description | type | sample |
|---|---|---|---|---|
| host | * | target cluster’s host | string | localhost |
| port | * | target cluster’s port | integer | 8081 |
dataset
- dataset which is used for executing job operation
- type: object
| property | mandatory | description | type | sample |
|---|---|---|---|---|
| name | * | dataset name | string enum: [fashion-mnist, original] | fashion-mnist |
| group | * | group name | string enum: [train, test, neighbors] | train |
| indexes | * | amount of index size | integer | 1000000 |
| range | * | range of indexes to be used (if there are many indexes, the range will be corrected on the job side) | object | - |
| range.start | * | start of range | integer | 1 |
| range.end | * | end of range | integer | 1000000 |
| url | the dataset url. It should be set when set name as original | string |
insert_config
- rpc config for insert request
- type: object
| property | mandatory | description | type | sample |
|---|---|---|---|---|
| skip_strict_exist_check | Check whether the same vector is already inserted or not. The ID should be unique if the value is true. | bool | false | |
| timestamp | The timestamp of the vector inserted. If it is N/A, the current time will be used. | string | 1707272658 |
update_config
- rpc config for update request
- type: object
| property | mandatory | description | type | sample |
|---|---|---|---|---|
| skip_strict_exist_check | Check whether the same vector is already inserted or not. The ID should be unique if the value is true. | bool | false | |
| timestamp | The timestamp of the vector inserted. If it is N/A, the current time will be used. | string | 1707272658 | |
| disable_balanced_update | A flag to disable balanced update (split remove -> insert operation) during update operation. | bool | false |
upsert_config
- rpc config for upsert request
- type: object
| property | mandatory | description | type | sample |
|---|---|---|---|---|
| skip_strict_exist_check | Check whether the same vector is already inserted or not. The ID should be unique if the value is true. | bool | false | |
| timestamp | The timestamp of the vector inserted. If it is N/A, the current time will be used. | string | 1707272658 | |
| disable_balanced_update | A flag to disable balanced update (split remove -> insert operation) during update operation. | bool | false |
upsert_config
- rpc config for search request
- type: object
| property | mandatory | description | type | sample |
|---|---|---|---|---|
| radius | The search radius. default: -1 | number | -1 | |
| epsilon | The search coefficient. default: 0.05 | number | 0.05 | |
| num | * | The maximum number of results to be returned. | integer | 10 |
| min_num | The minimum number of results to be returned. | integer | 5 | |
| timeout | Search timeout in nanoseconds default: 10s | string | 3s | |
| enable_linear_search | A flag to enable linear search operation for estimating search recall. If it is true, search operation with linear operation will execute. | bool | false | |
| aggregation_algorithm | The search aggregation algorithm option. default: Unknown | string enum: [“Unknown”, “ConcurrentQueue”, “SortSlice”, “SortPoolSlice”, “PairingHeap”] |
remove_config
- rpc config for remove request
- type: object
| property | mandatory | description | type | sample |
|---|---|---|---|---|
| skip_strict_exist_check | Check whether the same vector is already inserted or not. The ID should be unique if the value is true. | bool | false | |
| timestamp | The timestamp of the vector inserted. If it is N/A, the current time will be used. | string | 1707272658 |
object_config
- rpc config for get object request
- type: object
| property | mandatory | description | type | sample |
|---|---|---|---|---|
| filter_config.targets | filter target host and port for bypassing filter component. | []object |
ValdBenchmarkScenario
ValdBenchmarkScenario is used for executing single or multiple benchmark job.
Benchmark Operator decomposes manifest and creates benchmark resources one by one.
The target and dataset property are the global config for scenario, they can be overwritten when each job has own config.
main properties
| property | mandatory | description | type | sample |
|---|---|---|---|---|
| target | * | target Vald cluster information It will be overwritten when each job has own config | object | ref: target |
| dataset | * | dataset information It will be overwritten when each job has own config | object | ref: dataset |
| jobs | * | benchmark job config The jobs written above will be executed in order. | object | ref: benchmark job |
Deploy Benchmark Operator
Continuous benchmark operator can be applied with Helm same as Vald cluster.
It requires ValdBenchmarkOperatorRelease for deploying vald-benchmark-operator.
It is not must to apply, so please edit and apply as necessary.
Although it is possible to override using `ValdBenchmarkScenarioRelease` or `ValdBenchmarkJobRelease`, we recommend configuring common setting items here.
Sample ValdBenchmarkOperatorRelease YAML
# @schema {"name": "name", "type": "string"}
# name -- name of the deployment
name: vald-benchmark-operator
# @schema {"name": "time_zone", "type": "string"}
# time_zone -- time_zone
time_zone: ""
# @schema {"name": "image", "type": "object"}
image:
# @schema {"name": "image.repository", "type": "string"}
# image.repository -- image repository
repository: vdaas/vald-benchmark-operator
# @schema {"name": "image.tag", "type": "string"}
# image.tag -- image tag
tag: v1.7.5
# @schema {"name": "image.pullPolicy", "type": "string", "enum": ["Always", "Never", "IfNotPresent"]}
# image.pullPolicy -- image pull policy
pullPolicy: Always
# @schema {"name": "job", "type": "object"}
job:
# @schema {"name": "job.image", "type": "object"}
image:
# @schema {"name": "job.image.repository", "type": "string"}
# image.repository -- job image repository
repository: vdaas/vald-benchmark-job
# @schema {"name": "job.image.tag", "type": "string"}
# image.tag -- image tag for job docker image
tag: v1.7.12
# @schema {"name": "job.image.pullPolicy", "type": "string", "enum": ["Always", "Never", "IfNotPresent"]}
# image.pullPolicy -- image pull policy
pullPolicy: Always
# @schema {"name": "job.client_config", "type": "object"}
# client_config -- gRPC client config for request to the Vald cluster
client_config:
# @schema {"name": "job.client_config.addrs", "type": "array", "items": {"type": "string"}}
# job.client_config.addrs -- gRPC client addresses
addrs: []
# @schema {"name": "job.client_config.health_check_duration", "type": "string"}
# job.client_config.health_check_duration -- gRPC client health check duration
health_check_duration: "1s"
# @schema {"name": "job.client_config.connection_pool", "type": "object"}
connection_pool:
# @schema {"name": "job.client_config.connection_pool.enable_dns_resolver", "type": "boolean"}
# job.client_config.connection_pool.enable_dns_resolver -- enables gRPC client connection pool dns resolver, when enabled vald uses ip handshake exclude dns discovery which improves network performance
enable_dns_resolver: true
# @schema {"name": "job.client_config.connection_pool.enable_rebalance", "type": "boolean"}
# job.client_config.connection_pool.enable_rebalance -- enables gRPC client connection pool rebalance
enable_rebalance: true
# @schema {"name": "job.client_config.connection_pool.rebalance_duration", "type": "string"}
# job.client_config.connection_pool.rebalance_duration -- gRPC client connection pool rebalance duration
rebalance_duration: 30m
# @schema {"name": "job.client_config.connection_pool.size", "type": "integer"}
# job.client_config.connection_pool.size -- gRPC client connection pool size
size: 3
# @schema {"name": "job.client_config.connection_pool.old_conn_close_duration", "type": "string"}
# job.client_config.connection_pool.old_conn_close_duration -- makes delay before gRPC client connection closing during connection pool rebalance
old_conn_close_duration: "2m"
# @schema {"name": "job.client_config.backoff", "type": "object", "anchor": "backoff"}
backoff:
# @schema {"name": "job.client_config.backoff.initial_duration", "type": "string"}
# job.client_config.backoff.initial_duration -- gRPC client backoff initial duration
initial_duration: 5ms
# @schema {"name": "job.client_config.backoff.backoff_time_limit", "type": "string"}
# job.client_config.backoff.backoff_time_limit -- gRPC client backoff time limit
backoff_time_limit: 5s
# @schema {"name": "job.client_config.backoff.maximum_duration", "type": "string"}
# job.client_config.backoff.maximum_duration -- gRPC client backoff maximum duration
maximum_duration: 5s
# @schema {"name": "job.client_config.backoff.jitter_limit", "type": "string"}
# job.client_config.backoff.jitter_limit -- gRPC client backoff jitter limit
jitter_limit: 100ms
# @schema {"name": "job.client_config.backoff.backoff_factor", "type": "number"}
# job.client_config.backoff.backoff_factor -- gRPC client backoff factor
backoff_factor: 1.1
# @schema {"name": "job.client_config.backoff.retry_count", "type": "integer"}
# job.client_config.backoff.retry_count -- gRPC client backoff retry count
retry_count: 100
# @schema {"name": "job.client_config.backoff.enable_error_log", "type": "boolean"}
# job.client_config.backoff.enable_error_log -- gRPC client backoff log enabled
enable_error_log: true
# @schema {"name": "job.client_config.circuit_breaker", "type": "object"}
circuit_breaker:
# @schema {"name": "job.client_config.circuit_breaker.closed_error_rate", "type": "number"}
# job.client_config.circuit_breaker.closed_error_rate -- gRPC client circuitbreaker closed error rate
closed_error_rate: 0.7
# @schema {"name": "job.client_config.circuit_breaker.half_open_error_rate", "type": "number"}
# job.client_config.circuit_breaker.half_open_error_rate -- gRPC client circuitbreaker half-open error rate
half_open_error_rate: 0.5
# @schema {"name": "job.client_config.circuit_breaker.min_samples", "type": "integer"}
# job.client_config.circuit_breaker.min_samples -- gRPC client circuitbreaker minimum sampling count
min_samples: 1000
# @schema {"name": "job.client_config.circuit_breaker.open_timeout", "type": "string"}
# job.client_config.circuit_breaker.open_timeout -- gRPC client circuitbreaker open timeout
open_timeout: "1s"
# @schema {"name": "job.client_config.circuit_breaker.closed_refresh_timeout", "type": "string"}
# job.client_config.circuit_breaker.closed_refresh_timeout -- gRPC client circuitbreaker closed refresh timeout
closed_refresh_timeout: "10s"
# @schema {"name": "job.client_config.call_option", "type": "object"}
call_option:
# @schema {"name": "job.client_config.wait_for_ready", "type": "boolean"}
# job.client_config.call_option.wait_for_ready -- gRPC client call option wait for ready
wait_for_ready: true
# @schema {"name": "job.client_config.max_retry_rpc_buffer_size", "type": "integer"}
# job.client_config.call_option.max_retry_rpc_buffer_size -- gRPC client call option max retry rpc buffer size
max_retry_rpc_buffer_size: 0
# @schema {"name": "job.client_config.max_recv_msg_size", "type": "integer"}
# job.client_config.call_option.max_recv_msg_size -- gRPC client call option max receive message size
max_recv_msg_size: 0
# @schema {"name": "job.client_config.max_send_msg_size", "type": "integer"}
# job.client_config.call_option.max_send_msg_size -- gRPC client call option max send message size
max_send_msg_size: 0
# @schema {"name": "job.client_config.dial_option", "type": "object"}
dial_option:
# @schema {"name": "job.client_config.dial_option.write_buffer_size", "type": "integer"}
# job.client_config.dial_option.write_buffer_size -- gRPC client dial option write buffer size
write_buffer_size: 0
# @schema {"name": "job.client_config.dial_option.read_buffer_size", "type": "integer"}
# job.client_config.dial_option.read_buffer_size -- gRPC client dial option read buffer size
read_buffer_size: 0
# @schema {"name": "job.client_config.dial_option.initial_window_size", "type": "integer"}
# job.client_config.dial_option.initial_window_size -- gRPC client dial option initial window size
initial_window_size: 0
# @schema {"name": "job.client_config.dial_option.initial_connection_window_size", "type": "integer"}
# job.client_config.dial_option.initial_connection_window_size -- gRPC client dial option initial connection window size
initial_connection_window_size: 0
# @schema {"name": "job.client_config.dial_option.max_msg_size", "type": "integer"}
# job.client_config.dial_option.max_msg_size -- gRPC client dial option max message size
max_msg_size: 0
# @schema {"name": "job.client_config.dial_option.backoff_max_delay", "type": "string"}
# job.client_config.dial_option.backoff_max_delay -- gRPC client dial option max backoff delay
backoff_max_delay: "120s"
# @schema {"name": "job.client_config.dial_option.backoff_base_delay", "type": "string"}
# job.client_config.dial_option.backoff_base_delay -- gRPC client dial option base backoff delay
backoff_base_delay: "1s"
# @schema {"name": "job.client_config.dial_option.backoff_multiplier", "type": "number"}
# job.client_config.dial_option.backoff_multiplier -- gRPC client dial option base backoff delay
backoff_multiplier: 1.6
# @schema {"name": "job.client_config.dial_option.backoff_jitter", "type": "number"}
# job.client_config.dial_option.backoff_jitter -- gRPC client dial option base backoff delay
backoff_jitter: 0.2
# @schema {"name": "job.client_config.dial_option.min_connection_timeout", "type": "string"}
# job.client_config.dial_option.min_connection_timeout -- gRPC client dial option minimum connection timeout
min_connection_timeout: "20s"
# @schema {"name": "job.client_config.dial_option.enable_backoff", "type": "boolean"}
# job.client_config.dial_option.enable_backoff -- gRPC client dial option backoff enabled
enable_backoff: false
# @schema {"name": "job.client_config.dial_option.insecure", "type": "boolean"}
# job.client_config.dial_option.insecure -- gRPC client dial option insecure enabled
insecure: true
# @schema {"name": "job.client_config.dial_option.timeout", "type": "string"}
# job.client_config.dial_option.timeout -- gRPC client dial option timeout
timeout: ""
# @schema {"name": "job.client_config.dial_option.interceptors", "type": "array", "items": {"type": "string", "enum": ["TraceInterceptor"]}}
# job.client_config.dial_option.interceptors -- gRPC client interceptors
interceptors: []
# @schema {"name": "job.client_config.dial_option.net", "type": "object", "anchor": "net"}
net:
# @schema {"name": "job.client_config.dial_option.net.dns", "type": "object"}
dns:
# @schema {"name": "job.client_config.dial_option.net.dns.cache_enabled", "type": "boolean"}
# job.client_config.dial_option.net.dns.cache_enabled -- gRPC client TCP DNS cache enabled
cache_enabled: true
# @schema {"name": "job.client_config.dial_option.net.dns.refresh_duration", "type": "string"}
# job.client_config.dial_option.net.dns.refresh_duration -- gRPC client TCP DNS cache refresh duration
refresh_duration: 30m
# @schema {"name": "job.client_config.dial_option.net.dns.cache_expiration", "type": "string"}
# job.client_config.dial_option.net.dns.cache_expiration -- gRPC client TCP DNS cache expiration
cache_expiration: 1h
# @schema {"name": "job.client_config.dial_option.net.dialer", "type": "object"}
dialer:
# @schema {"name": "job.client_config.dial_option.net.dialer.timeout", "type": "string"}
# job.client_config.dial_option.net.dialer.timeout -- gRPC client TCP dialer timeout
timeout: ""
# @schema {"name": "job.client_config.dial_option.net.dialer.keepalive", "type": "string"}
# job.client_config.dial_option.net.dialer.keepalive -- gRPC client TCP dialer keep alive
keepalive: ""
# @schema {"name": "job.client_config.dial_option.net.dialer.dual_stack_enabled", "type": "boolean"}
# job.client_config.dial_option.net.dialer.dual_stack_enabled -- gRPC client TCP dialer dual stack enabled
dual_stack_enabled: true
# @schema {"name": "job.client_config.dial_option.net.socket_option", "type": "object"}
socket_option:
# @schema {"name": "job.client_config.dial_option.net.socket_option.reuse_port", "type": "boolean"}
# job.client_config.dial_option.net.socket_option.reuse_port -- server listen socket option for reuse_port functionality
reuse_port: true
# @schema {"name": "job.client_config.dial_option.net.socket_option.reuse_addr", "type": "boolean"}
# job.client_config.dial_option.net.socket_option.reuse_addr -- server listen socket option for reuse_addr functionality
reuse_addr: true
# @schema {"name": "job.client_config.dial_option.net.socket_option.tcp_fast_open", "type": "boolean"}
# job.client_config.dial_option.net.socket_option.tcp_fast_open -- server listen socket option for tcp_fast_open functionality
tcp_fast_open: true
# @schema {"name": "job.client_config.dial_option.net.socket_option.tcp_no_delay", "type": "boolean"}
# job.client_config.dial_option.net.socket_option.tcp_no_delay -- server listen socket option for tcp_no_delay functionality
tcp_no_delay: true
# @schema {"name": "job.client_config.dial_option.net.socket_option.tcp_cork", "type": "boolean"}
# job.client_config.dial_option.net.socket_option.tcp_cork -- server listen socket option for tcp_cork functionality
tcp_cork: false
# @schema {"name": "job.client_config.dial_option.net.socket_option.tcp_quick_ack", "type": "boolean"}
# job.client_config.dial_option.net.socket_option.tcp_quick_ack -- server listen socket option for tcp_quick_ack functionality
tcp_quick_ack: true
# @schema {"name": "job.client_config.dial_option.net.socket_option.tcp_defer_accept", "type": "boolean"}
# job.client_config.dial_option.net.socket_option.tcp_defer_accept -- server listen socket option for tcp_defer_accept functionality
tcp_defer_accept: true
# @schema {"name": "job.client_config.dial_option.net.socket_option.ip_transparent", "type": "boolean"}
# job.client_config.dial_option.net.socket_option.ip_transparent -- server listen socket option for ip_transparent functionality
ip_transparent: false
# @schema {"name": "job.client_config.dial_option.net.socket_option.ip_recover_destination_addr", "type": "boolean"}
# job.client_config.dial_option.net.socket_option.ip_recover_destination_addr -- server listen socket option for ip_recover_destination_addr functionality
ip_recover_destination_addr: false
# @schema {"name": "job.client_config.dial_option.keepalive", "type": "object"}
keepalive:
# @schema {"name": "job.client_config.dial_option.keepalive.time", "type": "string"}
# job.client_config.dial_option.keepalive.time -- gRPC client keep alive time
time: "120s"
# @schema {"name": "job.client_config.dial_option.keepalive.timeout", "type": "string"}
# job.client_config.dial_option.keepalive.timeout -- gRPC client keep alive timeout
timeout: "30s"
# @schema {"name": "job.client_config.dial_option.keepalive.permit_without_stream", "type": "boolean"}
# job.client_config.dial_option.keepalive.permit_without_stream -- gRPC client keep alive permit without stream
permit_without_stream: true
# @schema {"name": "resources", "type": "object"}
# resources -- kubernetes resources of pod
resources:
# @schema {"name": "resources.limits", "type": "object"}
limits:
cpu: 300m
memory: 300Mi
# @schema {"name": "resources.requests", "type": "object"}
requests:
cpu: 200m
memory: 200Mi
# @schema {"name": "logging", "type": "object"}
logging:
# @schema {"name": "logging.logger", "type": "string", "enum": ["glg", "zap"]}
# logging.logger -- logger name.
logger: glg
# @schema {"name": "logging.level", "type": "string", "enum": ["debug", "info", "warn", "error", "fatal"]}
# logging.level -- logging level.
level: debug
# @schema {"name": "logging.format", "type": "string", "enum": ["raw", "json"]}
# logging.format -- logging format.
format: raw
For more details of the configuration of vald-benchmark-operator-release, please refer to here
Add Vald repo into the helm repo
helm repo add vald https://vdaas.vald.orgDeploy
vald-benchmark-operator-releasehelm install vald-benchmark-operator-release vald/vald-benchmark-operatorApply
vbor.yaml(optional)kubectl apply -f vbor.yaml
Running Continuous Benchmarks
After deploy the benchmark operator, you can execute continuous benchmark by applying ValdBenchmarkScenarioRelease or ValdBenchmarkJobRelease.
Please configure designed benchmark and apply by kubectl command.
The sample manifests are here.
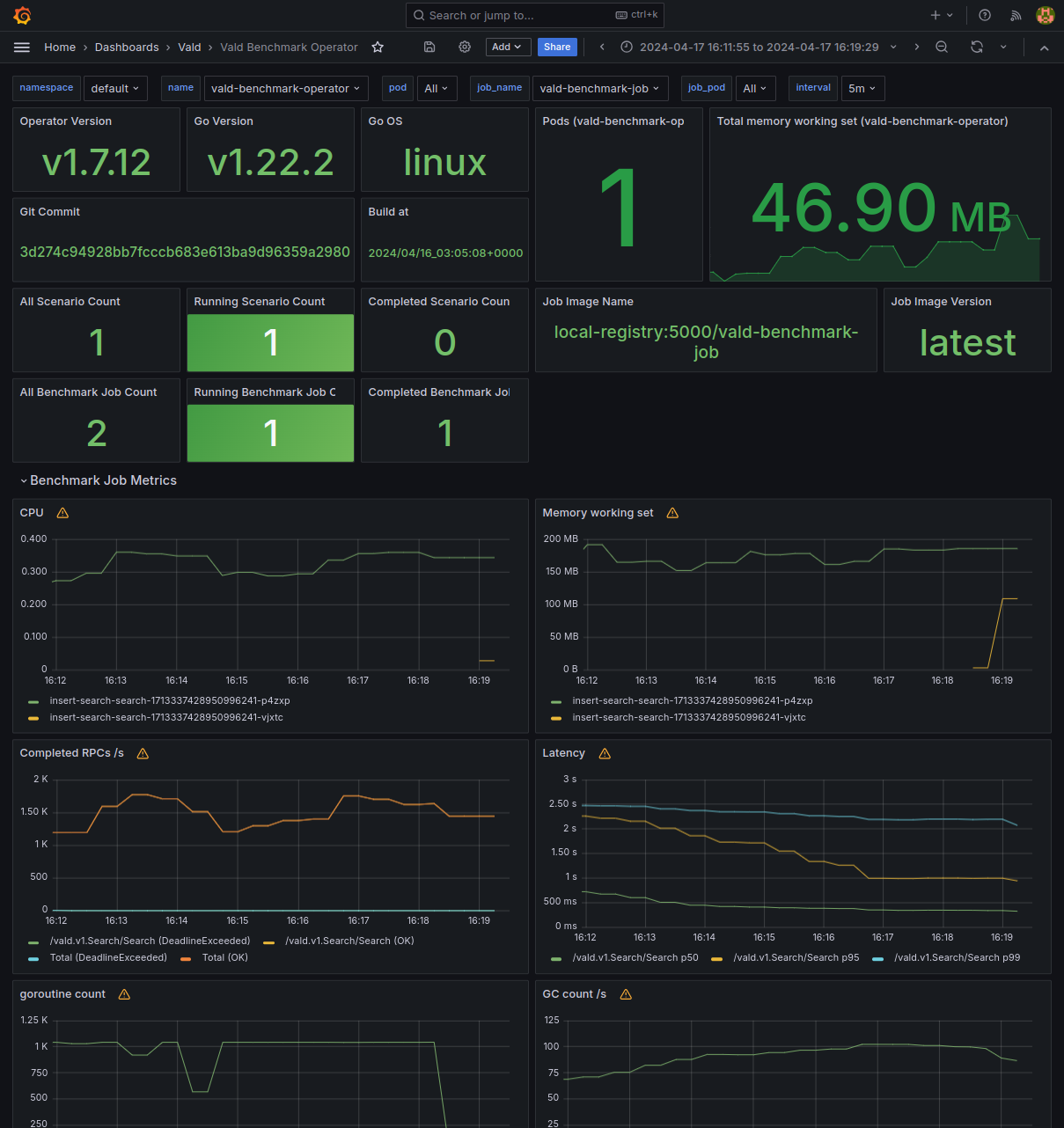
Monitoring Benchmark Job Metrics
Metrics monitoring can be set in the same way as Vald cluster. For information on building a monitoring environment, please refer to Observability Configuration.
To monitor metrics about continuous benchmarking, please edit ValdBenchmarkOperatorRelease as follows:
---
# @schema {"name": "observability", "type": "object"}
observability:
# @schema {"name": "observability.enabled", "type": "boolean"}
enabled: true
# @schema {"name": "observability.otlp", "type": "object"}
otlp:
# @schema {"name": "observability.otlp.collector_endpoint", "type": "string"}
# Please confirm correct collector_endpoint
collector_endpoint: "opentelemetry-collector-collector.default.svc.cluster.local:4317"
trace:
# @schema {"name": "observability.trace.enabled", "type": "boolean"}
enabled: true
After apply it, the metrics can be shown on the Grafana dashboard like as below.